ingrAIdients - ingredient detection from images
AI & ML · Coursework · 2024
ingrAIdients is a course project where we built a vision pipeline that predicts ingredients directly from food images, then uses an LLM to turn those predictions into recipe-style text. The project was an exploration of multi-label classification, representation learning, and how computer vision and language models can be combined into a more user-facing product experience.
- Task: multi-label ingredient prediction from food images
- Approach: Vision Transformer with a fine-tuned classification head
- Extension: LLM-generated dish descriptions and recipe-style outputs
- Focus: vision, representation learning, and product-oriented AI design
Problem and data
Most recipe or nutrition apps start with a dish name, barcode, or manual ingredient list. We wanted to explore the opposite workflow: starting from a food photo and predicting what ingredients are likely present. That turns the problem into a multi-label vision task, where one image may correspond to many overlapping ingredients rather than a single class.
We built a curated dataset by combining existing food image sources, cleaning noisy labels, and grouping overly specific ingredients into more useful categories. For example, multiple cheese or sauce labels were collapsed into broader ingredient groups to make the prediction task more stable and practical.
Each image was ultimately paired with a binary ingredient vector over a controlled vocabulary, which gave us a more consistent training target for multi-label classification.
Model architecture
The final model used a Vision Transformer (ViT) as the image encoder with a lightweight classification head to produce ingredient logits. Earlier experiments with ResNet-based models and CNN plus sequence-style setups informed the direction, but ViT gave the best balance between performance, flexibility, and training stability.
- Images were resized and augmented to improve generalization across food presentation styles.
- The ViT backbone was initialized from pretrained weights, with later layers and the classification head fine-tuned for the task.
- Sigmoid outputs with binary cross-entropy loss were used for multi-label prediction.
- Prediction thresholds were tuned on validation performance rather than fixed uniformly across all ingredient classes.
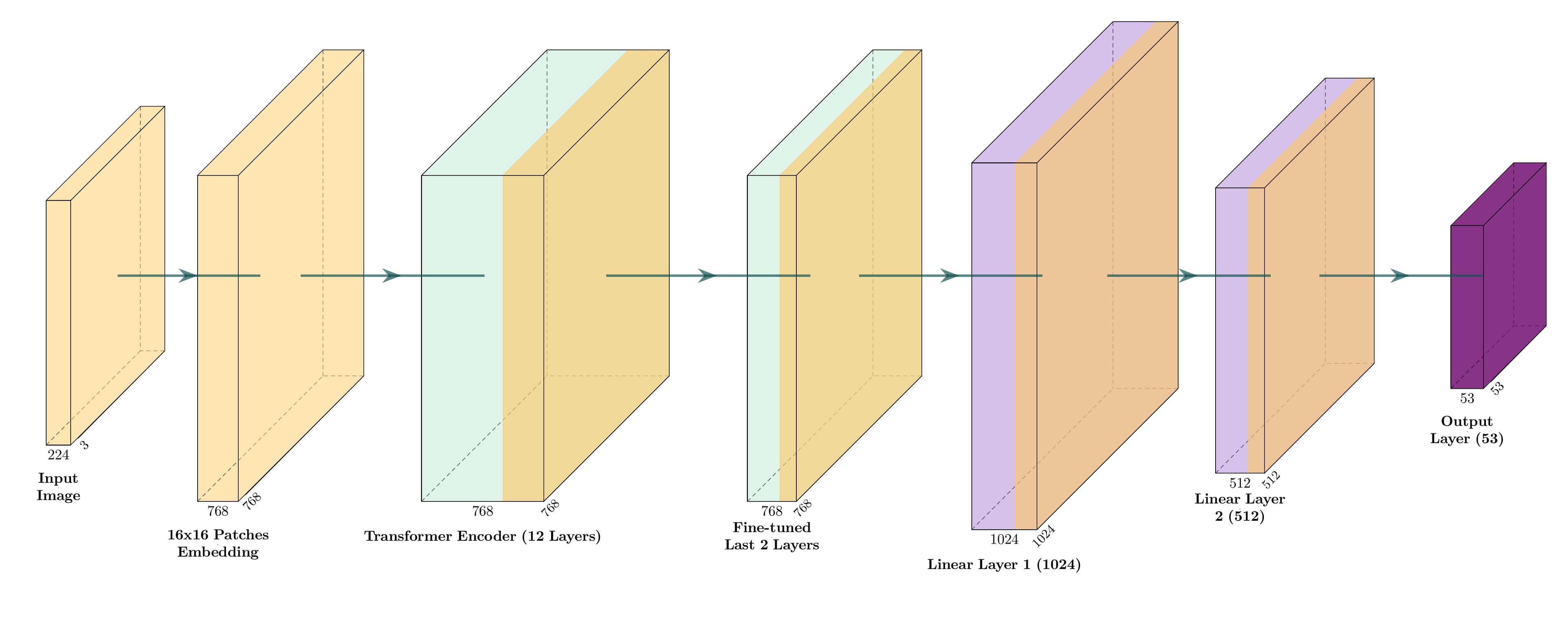
High-level pipeline: food images are encoded by a Vision Transformer, converted into ingredient predictions, and then passed into an LLM layer to produce natural-language dish and recipe-style outputs.
Performance and insights
We evaluated the model using subset accuracy, per-class F1, and mean average precision. Performance was strongest on common and visually distinctive ingredients, while rarer or more subtle classes remained more difficult.
One of the most interesting findings was that many incorrect predictions were still semantically close to the target. The model might predict a broader ingredient category instead of a specific herb or sauce, which is still useful in downstream settings even if it is not an exact match.
That pushed us to think beyond strict label accuracy and ask whether the predictions were useful enough for applications like recipe generation, approximate nutrition estimation, or food understanding interfaces.
LLM layer and product thinking
A raw ingredient vector is technically useful, but not especially user-friendly. To make the system feel more like a real product, we added an LLM layer that takes the predicted ingredients and turns them into more natural outputs.
- a short description of the likely dish, and
- an approximate recipe-style outline based on the detected ingredients.
This part of the project helped bridge the gap between model output and user experience. It also showed how vision and language systems can be combined to create something more intuitive than either model on its own.
Ethics and limitations
We also looked at the broader design challenges around a system like this. These included cultural bias in food datasets, uncertainty for dietary restrictions and allergens, and privacy concerns around image capture and storage.
The project report explores how a production system could handle consent, opt-out, and possibly on-device inference to reduce privacy concerns while making predictions more trustworthy for users.
Tech stack
- PyTorch and torchvision
- Vision Transformer backbone with pretrained initialization
- Multi-label classification with binary cross-entropy loss
- Albumentations for image augmentation
- LLM API for recipe-style text generation
- Weights and Biases for experiment tracking